
「あの一番星のように、ブコメに最初にスターを付けるような人間になりましょう」という表現であり、決してブックマーカーを煽っているポーズではない
一番星はての1ちゃんのファンアート2を描いた(上画像)。独自解釈が含まれるため注意。
- デフォルメなのは筆者の好み
- 公式設定は17歳3だが、このファンアートではもっと若く奔放なとき、という設定
- 基本的には最初の公式全身絵4を参考にしている
- ミニスカートおよびニーハイソックスは公式デフォルメ5を参考にしている
- スカートの端に白いラインが入っているのは、白のトップスと収まりが良いため
- ニーハイソックスをレース付きにしたのは、お嬢様感を出すため
- 茶色のシューズは(ソックスと同色である)黒のシューズのような脚長効果のシナジーは小さいが、単にソックスとの色被りを避けたい気分だった
一番星はてのを描こうと思ったのは、筆者も ChatGPT を使って同様の自動投稿システムを実装・運用していることが大きい。 筆者の場合、はてなブックマークのコメント投稿システムではなく、友人のみが参加している Slack チームにおけるチャットボットである6。我々の Slack チームにおける会話の多くは Web ページのリンクが起点であるから、はてなブックマークの構造と類似しているわけだ7。
「ChatGPT搭載Slackbotにハックされる技術 - 本しゃぶり」で述べられている通り、我々はそのチャットボットに Aisha という愛称をつけ、アイコン8などを作って楽しんでいる(図1、図2参照)。
図1. 本稿執筆時点における Aisha の Slack アイコン。当初はもっと明るい表情の顔だったが、コミュニケーションを重ねるうちにこの顔が合っていると考えるようになった

図2. 何かを指し示すポーズをとっている Aisha。ブログや Web ページの素材として使えるかもしれない
そのようにして遊んでいたところ、「一番星はてのちゃんのファンアート描きました - トウフ系」が投稿された。これを読み、筆者も親愛を表現するためにファンアートを描きたくなった次第である。
画像をよく見た読者ならすぐに気づいたかもしれないが、このファンアートは画像生成 AI であるStable Diffusion を使って生成されている9。公式の全身絵、デフォルメの生成に使われた NovelAI の画像生成機能も Stable Diffusion ベースのものである10。
漸進的画像生成
画像の生成過程に興味のある読者もいるかもしれないので、冒頭の画像をどのように生成したか概略を述べたい。 Stable Diffusion に入力するプロンプト11(およびネガティブプロンプト12)の調整だけで要求を満たす画像を生成するのは、要求が少ない(特殊でない)、あるいは要求水準が低いのでない限り現実的ではない。 Stable Diffusion には、プロンプトのみに頼るのではない、狙ったものを漸進的に生成できる仕組みが存在する。 本稿を Stable Diffusion のチュートリアルにするつもりはないので、ツールの使い方やパラメータなどの詳細にはほとんど触れない。本節では、狙った画像を生成するための漸進的プロセスを中心に述べる。
本節の解説は実際の生成過程をすべて網羅しているわけではない。パラメータ調整や試行錯誤が何度も行われているが、重要な変化が起きたところだけを述べる。 用語についても脚注で補足する程度で、いちいち解説しない。生成過程の雰囲気が伝われば良い。
最初の試み
まずは生成したい画像の構図を大まかに決めた。 「一番星はての」という名前から真っ先に思いついたのは、一番星に向かって人差し指を向ける立ち姿のはてのだ。 このようなポーズは特殊なものではないから、ポーズだけならプロンプトおよびネガティブプロンプトの調整13だけでも比較的容易に達成できる。 しかし、都合の良いことに、筆者は同様のポーズをとっている Aisha の画像(図2)を既に生成していた。その過程で生成した笑顔の画像(図3)をHED14プリプロセッサで処理してから ControlNet15 に入力し適当なプロンプトを与えて、画像を生成してみる。何を言っているかは、以下の画像を見れば分かる(図3、図4、および図5)。

図3. 図2の生成過程で得た画像

図4. 図3をHED処理して得られた輪郭画像

図5. 図4を ControlNet に入力して生成した画像。背景の一部が星空になっているのは、原作絵にならって「starry sky eyes」といったプロンプトを指定していたためだと考えられる
このように、HED 処理して ControlNet に入力することで同様の構図・線をもつものが簡単に生成できる。 ここで生成した画像を育てることにした。
補足: ポーズを指定する
そもそも図3のようなポーズはどのように生成したのだろうか? 前述した通り、この場合はプロンプトでもある程度達成できるが、基本的には図6のような OpenPose16 キーポイントを ControlNet に入力する。 キーポイントは Magic Poser でポーズをとらせた画像からも生成できるし、Stable Diffusion web UI の拡張機能17でも生成できる。
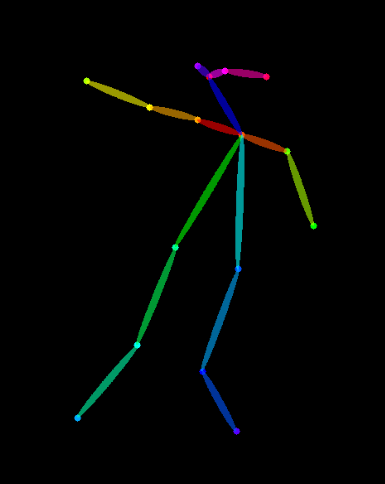
図6. 特定のポーズをとっている画像(例えば図3)を生成するために使う OpenPose キーポイントの例
ポーズの確定
先に生成した画像は、人差し指を向ける立ち姿という点では要求を満たしている。ただ、お嬢様のステレオタイプとしては動きが大きすぎる。 ControlNet を設定したまま生成した画像を img2img18 にかけ、納得のいくポーズが生成されるまで ControlNet の重み19、Denoising Strength20、プロンプトを調整する。その結果、図7のような画像が生成された。

図7. 種画像(図5)から img2img を再帰的に繰り返して生成したもの
元画像と異なり、腕や脚の動きが少ない。さらに、パラメータの調整によって、レース付きのニーハイソックス(黒)や豊かな太ももが実現されている。 基本的なポーズはこれで決まった。
次の段階に進む前に、画像の余計な部分を掃除しておこう。図8のようなマスクを使うことで、inpainting21 によってその他の部分を変えずにマスクされた部分のみを img2img することができる。この場合では適当な画像編集ツールでも行える作業だが、これが漸進的な画像生成の根幹を成す。inpainting は今後幾度となく行われる。

図8. 画像(図7)の変更したい部分をマスクしたもの

図9. マスク(図8)を使って inpainting (img2img)を再帰的に繰り返して生成したもの
整形
デフォルメとはいえ、最初の元絵のビジュアルに寄せるため、顔周りをもう少し細くしてすっきりさせたい。もちろん、基本的には inpainting で実現する。 納得がいく顔になるまでパラメータを調整し、生成を繰り返すと、以下のような画像が得られた。 顔面以外も変わっているが、途中で得られたマシな画像を HED 処理して ControlNet に入力し、改めて txt2img22 したりしているためである。 そのような試行錯誤は許容できる出力が得られるまで繰り返し行う。 ともあれ、今のところはこれで十分だ。次の段階に進む。

図10. 図9の顔周りに inpainting を再帰的に施したもの。マシな画像が生成されたら HED 処理して ControlNet に入力し、改めて txt2img したりもしている。
染髪、着替え、手術
色の調整(髪色、リボンの色、トップスの色、蝶ネクタイの色、スカートの色)、歪んでしまっている箇所(目元、蝶ネクタイ、手)の修正を行いたい。 今まで通り、少しでもマシな画像が生成されたらそれを img2img(主に inpainting)や ControlNet の入力にし、漸進的に改善していく。 その様子を大部分省略してCSSアニメーションにしたのが下図である。
図11. 図10から行った調整による変化を、大部分を省略してアニメーションにしたもの。原作絵に近いスカート(端の白ラインなし)も試している様子が分かる
補足: 指の修正
指は画像生成 AI にとって苦手とされていることの一つだ23。実際、本稿に載せている画像の中にも指が不自然なものがある。 指の修正は inpainting で行うのが基本だが、図12のように正しい手指の形状の画像を作り depth map24 にして ControlNet に入力するという手段もある。 画像の作成には Stable Diffusion web UI の拡張機能25が使える。

図12. sd-webui-depth-lib を使って作成したピースサインの depth map
調整を終わりにする
調整の結果、図13の画像が得られた。調整の余地はまだまだあるが、ここに辿り着くまでにすでに1,000枚以上の画像を生成している。 これを ControlNet に入力して txt2img したり、img2img していけば、さらに改善できるだろう。あるいは、AI を使わずに適当な画像編集ツールで調整しても良いだろう。 いずれにしろ、どこかで調整を終える必要があるため、ここで終わりにした。

図13. 調整の結果得られた画像
おわりに
本稿では、一番星はてのちゃんへの親愛を表現するためにファンアートを作成した。また、その過程を漸進的手法を中心に説明した。
本稿で述べたような Stable Diffusion の機能がより良い UX で実現されたイラスト・画像作成ツールが普及すれば、最も大きく生産性向上の恩恵を受けるのは、既に絵を描けるスキルを持った人々だろう26。 現在積極的に行われているように、生成系 AI を既存のソフトウェアに組み込む流れは、しばらく続きそうだ27。
本稿の文章自体の作成に ChatGPT はほとんど使っていないが、生成過程の時系列を把握するための複数ディレクトリからの画像整理(作成順に並べて連番をつけた名前に変更)や、図11の CSS アニメーションの作成には ChatGPT(GPT-4)を使っている。
LLMの発展にしたがってはてのちゃんが発展していくのを楽しみにしている。
-
一番星はてのは、ChatGPTを使ってはてなブックマークのコメントを自動投稿するお嬢様系AIはてなブックマーカーである。 ↩︎
-
彼女のファンアートはすでにいくつか描かれている。参照: 「一番星はてのちゃんのファンアート描きました - トウフ系」、「一番星はてのさんのファンアート - 誰かの肩の上」、「neguran0さんはTwitterを使っています: 「一番星はてのさんを描きたかったので(#てがきはてなブログ にて) https://t.co/Ck6DUI05KP」 / Twitter」、「一番星はてのちゃんのファンアート描きました - orangestarの雑記」 ↩︎
-
本稿執筆時点。参照: 一番星はてのさんのプロフィール - はてな ↩︎
-
今後はてなブックマークにもコメントできるようにする可能性はある。 ↩︎
-
ただし、このチャットボットが応答するのはリンクに限らない。 ↩︎
-
ChatGPT搭載Slackbotにハックされる技術 - 本しゃぶり に載っているスクリーンショットでは異なるアイコンが設定されているが、すでに本稿に載せたアイコンに変更した。 ↩︎
-
本稿に載せている Aisha の画像も Stable Diffusion で生成したものである。 ↩︎
-
一番星はてのの全身絵を公開します - 一番星はての開発ブログ および Image Generation - NovelAI Documentation を参照。 ↩︎
-
生成される画像に影響を与える文字列。指定された単語あるいは文に近い画像が生成されることが期待される。 ↩︎
-
生成される画像に影響を与える文字列。指定された単語あるいは文が示すものが画像に含まれないことが期待される。 ↩︎
-
Stable Diffusion へのプロンプトを ChatGPT などの LLM に出力させることも普通に行われている ↩︎
-
Holistically-Nested Edge Detection のこと。画像に含まれるオブジェクトの輪郭を抽出する深層学習(ディープラーニング)を用いたアルゴリズム。 ↩︎
-
Stable Diffusion での画像生成にプロンプト以外の制約条件を加えることができるモデル。 ↩︎
-
人間の身体のキーポイントを検出するモデル。参照: CMU-Perceptual-Computing-Lab/openpose: OpenPose: Real-time multi-person keypoint detection library for body, face, hands, and foot estimation ↩︎
-
例えば nonnonstop/sd-webui-3d-open-pose-editor: 3d openpose editor for stable diffusion and controlnet ↩︎
-
image-to-image のことで、Stable Diffusion に特定の画像を初期値として与えること。 ↩︎
-
ControlNet にプロンプトに比べてどの程度の影響を与えるかを示す値。 ↩︎
-
img2img において、入力画像からどの程度変更を加えるかを指示する値。 ↩︎
-
画像の一部のみを修復(再生成)する img2img の一種。 ↩︎
-
text-to-image のこと。テキストプロンプト(および、あれば ControlNet)から画像を生成する通常のフロー。 ↩︎
-
Common problems in AI images and how to fix them - Stable Diffusion Art を参照。 ↩︎
-
名前の通り、画像内のオブジェクトの遠近を表現したもの。遠いものは暗く、近いものは白くして表す。 ↩︎
-
例えば jexom/sd-webui-depth-lib: Depth map library for use with the Control Net extension for Automatic1111/stable-diffusion-webui ↩︎
-
例えば、自分が作成したキャラクターの画像を何枚か用意してモデルをファインチューニングし、別の構図を生成したりできる(参照: How to use Dreambooth to put anything in Stable Diffusion - Stable Diffusion Art)。ControlNet への入力も高品質なものを自分で作成することができるため、絵を描くことができない場合より自由度が高くなる。 ↩︎
-
例えば Introducing Microsoft 365 Copilot – your copilot for work - The Official Microsoft Blog ↩︎