
情報を電子媒体に記録する重要なメリットの一つは、電子計算機による高速検索である。 インターネットや検索エンジンといったテクノロジーによりそれが公然となって久しい1。
DuckDuckGo や Google といった Web サイト横断2の強力な検索サービスが存在する一方、あらゆる Web サイトで独自のサイト内検索機能が存在する3。 それらは主に動的 Web サイト4で実現され、Web アプリケーションの文脈で扱われるが、静的 Web サイト5においても実現可能だ6。
本稿では、本サイトで使用している静的サイトジェネレータである Hugo 7において、サイト内検索機能を安価に実装する方法を示す。
本稿で述べる検索機能は、本サイトの検索ページで実際に動作している。
要求
本サイトにおける検索機能の要求は以下の通り。
- 検索のためにサーバを追加したり外部サービスを使ったりしない8
- ビルドフローを複雑にしない
- 全文検索を行う
- 検索条件にマッチしたテキストをハイライトする9
- スペース区切り10による AND 検索を行う
- それぞれの検索語の完全一致のみ行う11
- 検索条件の入力に応じて追加の操作なしに検索結果を提示する12
- 検索結果は検索語の登場回数が多い順に表示する13
もちろん、要求はサイトによって異なるのが普通であり、汎用性には限界がある。 これらの要求は、収益化していない、かつページ数の少ない個人サイトにとって都合が良い。
実装
検索機能の実装の概略は以下である。
- 検索インデックスを JSON として返すエンドポイントを作る
- 検索ページで実行するスクリプトを作る。このスクリプトがクライアント側で実行され、検索インデックスの取得、検索の実行、結果の提示を行う
- 検索ページを作る(上記のスクリプトを読み込む)
この方法は、Hugo で作られたものに限らずあらゆる静的サイトで実現可能だが、実装の容易さや簡潔さは Hugo の優れた拡張性に依るところが大きい。
検索インデックス
Hugo は HTML だけでなく様々な出力フォーマットに対応しており、JSON も例外ではない。 まずは設定ファイルに下記を追加して、ホームにおいて JSON を出力できるようにしよう。
config.toml14
[outputs]
home = ["HTML", "RSS", "JSON"]
# /index.json 以外のパス、例えば /search/index.json にしたい場合は、
# section = ["HTML", "JSON"] のようにする必要がある
次に、検索インデックスを出力するページを作る。
layouts/_default/index.json
{{- $index := slice -}}
{{- range where .Site.RegularPages.ByDate.Reverse "Type" "not in" (slice "page" "json") -}}
{{ if .Params.dateCreated }}
{{ $.Scratch.Set "date" (.Params.dateCreated) }}
{{ else }}
{{- if isset site.Params "date_format" -}}
{{- $.Scratch.Set "date" (.Date.Format site.Params.date_format) -}}
{{- else -}}
{{- $.Scratch.Set "date" (.Date.Format "2006-01-02") -}}
{{- end -}}
{{ end }}
{{- $index = $index | append (dict "title" ( .Title | plainify ) "permalink" .Permalink "section" (i18n (.Section | title)) "tags" (apply .Params.tags "i18n" "." ) "categories" (apply .Params.categories "i18n" "." ) "content" (.Content | markdownify | htmlUnescape | plainify) "date" ($.Scratch.Get "date") ) -}}
{{- end -}}
{{- $index | jsonify -}}
記述が込み入っているが、サイト内の全てのページのタイトル、アドレス、タグ、カテゴリ、本文、作成日を JSON で返しているだけである15。
動作は下記のコマンドで容易に確かめられる。
curl http://localhost:1331/index.json
結果は以下のようになる16。
[
{
"categories": [],
"content": "Netlify は Web アプリケーションや静的 Web サイトのホスティングサービスだ。 # 後略",
"date": "2021-05-05",
"permalink": "http://localhost:1331/archives/migrating-to-vercel-from-netlify-due-to-performance-issues/",
"section": "",
"tags": [],
"title": "Netlify が遅いので Vercel に移行した"
},
{
"categories": [],
"content": " AWS (Amazon Web Services) には数多くのサービスがある1。 # 後略",
"date": "2021-02-15",
"permalink": "http://localhost:1331/archives/does-aws-session-manager-dream-of-ssh/",
"section": "",
"tags": [],
"title": "AWS Session Manager は SSH の夢を見るか?"
},
...
]
クライアント側でこの検索インデックスを取得すれば、(原理的には)如何なる検索も可能であることが分かるだろう。
検索アルゴリズム
検索アルゴリズムは TypeScript で記述する。 Hugo は esbuild によって TypeScript のビルドをサポートしており、特別な設定なしで TypeScript を利用できる17。
検索アルゴリズムは、検索条件を複数の検索語に分け、全ての検索語を含むページを探すという単純なものである。但し、以下の点が特殊だ。
- ハイライトのために、各ページの最初のマッチとその周辺のテキストを取り出し、取り出したテキスト内でのマッチ位置を計算する
- タイトルと本文の両方を検索対象にしつつマッチ位置の計算を簡単にするため、タイトルと本文を改行文字でつないだものを検索対象とする18
インターフェースは、以下のように使う Searcher として与える。
const data = [...] // 検索インデックス
const searcher = Searcher(data)
seacher.search('apple orange') // 検索条件を入力とする
// 検索結果: 返り値
[
{
item: {...}, // インデックスの要素と同じ
score: 2, // スコア(検索語の登場回数の合計)
firstMatchedPart: { // 最初のマッチ部分(ハイライトで使う)
part: 'apples are not oranges', // マッチ部分とその周辺
positions: [[0, 4], [15,20]], // part 内でのマッチ部分の位置
}
}
]
ここでは、自動テストの記述に Jest を使う(設定方法は付録を参照)。
assets/scripts/searcher.test.ts
// SearchIndex は検索インデックスの interface
// combineProperties は前述したタイトルと本文をつなげる関数
import { Searcher, SearchIndex, combineProperties } from './searcher'
const craftIndices = (): SearchIndex[] => [
{
content: 'Six by nine. Forty two.',
date: '1982-12-29',
permalink: 'https://www.lambdar.me/archives/hg2g3',
title: 'Life, the Universe and Everything',
},
{
content: 'Six by nine. Fifty six.',
date: '1992-10-12',
permalink: 'https://www.lambdar.me/archives/hg2g5',
title: 'Mostly Harmless',
},
{
content: 'Six by nine. Sixty six.',
date: '1979-10-12',
permalink: 'https://www.lambdar.me/archives/hg2g1',
title: `Don't Panic!`,
},
]
describe('Searcher', () => {
describe('#search()', () => {
it('should search titles', () => {
const indices = craftIndices()
const searcher = Searcher(indices)
const results = searcher.search('universe')
const expectedToMatch = indices[0]
expect(results).toStrictEqual([
{
item: expectedToMatch,
score: 1,
firstMatchedPart: {
part: combineProperties(expectedToMatch),
positions: [[10, 17]],
},
},
])
})
it('should search contents', () => {
const indices = craftIndices()
const searcher = Searcher(indices)
const results = searcher.search('fifty')
const expectedToMatch = indices[1]
expect(results).toStrictEqual([
{
item: expectedToMatch,
score: 1,
firstMatchedPart: {
part: combineProperties(expectedToMatch),
positions: [[29, 33]],
},
},
])
})
it('should search by AND', () => {
const indices = craftIndices()
const searcher = Searcher(indices)
const results = searcher.search('by panic')
const expectedToMatch = indices[2]
expect(results).toEqual([
{
item: expectedToMatch,
score: 2,
firstMatchedPart: {
part: combineProperties(expectedToMatch),
positions: expect.arrayContaining([
[17, 18],
[6, 10],
]),
},
},
])
})
it('should sort results by score', () => {
const indices = craftIndices()
const searcher = Searcher(indices)
const results = searcher.search('six')
expect(results).toEqual([
{
item: indices[2],
score: 3,
firstMatchedPart: {
part: combineProperties(indices[2]),
positions: expect.arrayContaining([
[13, 15],
[26, 28],
[32, 34],
]),
},
},
{
item: indices[1],
score: 2,
firstMatchedPart: {
part: combineProperties(indices[1]),
positions: expect.arrayContaining([
[16, 18],
[35, 37],
]),
},
},
{
item: indices[0],
score: 1,
firstMatchedPart: {
part: combineProperties(indices[0]),
positions: expect.arrayContaining([[34, 36]]),
},
},
])
})
})
})
上記のテストを満たす実装は以下。
assets/scripts/searcher.ts
// 検索インデックス(の要素)
export interface SearchIndex {
content: string
date: string
permalink: string
title: string
}
// 検索結果(の要素)
export interface SearchResult {
item: SearchIndex
score: number
firstMatchedPart: SearchMatchedPart
}
export type SearchTermMatch = RegExpMatchArray[]
// マッチ部分とその周辺を表す
export interface SearchMatchedPart {
part: string
positions: [number, number][]
}
const parseQuery = (query: string): string[] =>
query.split(/[ ]/).filter((term) => term)
const sum = (arr: number[]): number => arr.reduce((acc, elem) => acc + elem, 0)
const getScore = (matches: SearchTermMatch[]) =>
sum(matches.map((match) => match.length))
// 検索語中の正規表現をエスケープする
// 参考: https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Regular_Expressions#escaping
const escapeRegExp = (s: string): string =>
s.replace(/[.*+?^${}()|[\]\\]/g, '\\$&')
const findMatches = (s: string, term: string) => [
...s.matchAll(new RegExp(escapeRegExp(term), 'ig')),
]
// 最初のマッチ部分とその周辺テキストを抽出する関数。
// maxLength は、抽出されるテキスト全体の長さを表す。
// マッチ部分が中央になるように抽出される。
const getFirstMatchedPart = (
matches: SearchTermMatch[],
maxLength = 150
): SearchMatchedPart => {
const [firstTermMatch] = matches
const firstMatch: RegExpMatchArray = firstTermMatch[0]
if (
typeof firstMatch.index === 'undefined' ||
typeof firstMatch.input === 'undefined'
) {
throw new Error(
'unexpected error: RegExpMatchArray should contain index and input'
)
}
const origStart = firstMatch.index
const origEnd = origStart + firstMatch[0].length - 1
const length = origEnd - origStart + 1
const surroundLength = Math.max(maxLength - length, 0)
const start = Math.max(origStart - Math.floor(surroundLength / 2), 0)
const end = start + maxLength - 1
const part = firstMatch.input.slice(start, end)
const positions = matches.reduce((acc, match) => {
match.forEach((m) => {
if (typeof m.index === 'undefined' || typeof m.input === 'undefined') {
throw new Error(
'unexpected error: RegExpMatchArray should contain index and input'
)
}
const s = m.index
const e = m.index + m[0].length - 1
if (start <= s && e <= end) {
acc.push([s - start, e - start])
}
})
return acc
}, [] as [number, number][])
return {
part,
positions,
}
}
// タイトルと本文をつなげる関数
export const combineProperties = (item: SearchIndex) =>
`${item.title}\n${item.content}`
// メインのインターフェース
export const Searcher = (searchIndices: SearchIndex[]) => ({
search: (query: string): SearchResult[] => {
const terms = parseQuery(query)
if (!terms.length) {
return []
}
return searchIndices
.reduce((acc, item) => {
const combined = combineProperties(item)
const matches = terms.map((term) => findMatches(combined, term))
if (matches.some((match) => !match.length)) {
return acc
}
acc.push({
item,
score: getScore(matches),
firstMatchedPart: getFirstMatchedPart(matches),
})
return acc
}, [] as SearchResult[])
.sort((a: SearchResult, b: SearchResult) => b.score - a.score)
},
})
テストが通ることを確認してから進もう。
ハイライト
ハイライトはマッチ部分を表す SearchMatchedPart を入力とし、マッチ部分を強調するマークアップを行った文字列を返す。
インターフェースは、単純な関数 highlight で良い。
特殊な点は、スタイリングに Tailwind CSS を用いていることである。 大量のユーティリティクラスが定義されているため、大抵の場合自分で CSS を書かなくて良い。
自動テストを以下に示す。
assets/scripts/highlight.test.ts
import { SearchResult, combineProperties, SearchIndex } from './searcher'
// markupHighlight はマークアップのみを行う関数
import { highlight, markupHighlight } from './highlight'
const craftItem = () => ({
content: 'Six by nine. Forty two.',
date: '1982-12-29',
permalink: 'https://www.lambdar.me/archives/hg2g3',
title: 'Life, the Universe and Everything',
})
const craftResults = (item: SearchIndex): SearchResult[] => [
{
item,
score: 3,
firstMatchedPart: {
part: combineProperties(item),
positions: [
[23, 32], // Everthing
[47, 51], // Forty
[53, 55], // Two
],
},
},
]
describe('highlight', () => {
it('should highlight all matches', () => {
const item = craftItem()
const results = craftResults(item)
const highlighted = highlight(results[0].firstMatchedPart)
expect(highlighted).toEqual(
`Life, the Universe and ${markupHighlight(
'Everything'
)}\nSix by nine. ${markupHighlight('Forty')} ${markupHighlight('two')}.`
)
})
})
上記のテストを満たす実装は以下。
assets/scripts/highlight.ts
import { SearchMatchedPart } from './searcher'
// マークアップのみを行う関数
export const markupHighlight = (s: string): string =>
`<span class="text-red-500">${s}</span>`
// メインのインターフェース
export const highlight = (matchedPart: SearchMatchedPart): string => {
const { part, positions } = matchedPart
let highlighted = ''
positions.forEach(([s, e], i) => {
const before = part.slice(highlighted.length, s)
const matched = part.slice(s, e + 1)
const after =
positions.length > i + 1
? part.slice(e + 1, positions[i + 1][0])
: part.slice(e + 1)
highlighted += `${before}${markupHighlight(matched)}${after}`
})
return highlighted
}
こちらも、テストが通ることを確認してから進むと良い。
検索 UI
Searcher と highlight を使い、検索 UI のスクリプトを完成させる。
主に以下を行う。
- 検索条件入力フォームにフォーカスしたときに検索インデックスをロードする
- 検索インデックスのロード中はローディングスピナーを表示する
- keyup イベントにおいて検索を実行して結果およびその件数を表示する
コードは以下。
assets/scripts/search.ts
import { Searcher, SearchResult } from './searcher'
import { highlight } from './highlight'
// 検索条件入力フォーム
const searchInput = document.getElementById('search-input') as HTMLInputElement
// ローディングスピナーの表示領域
const searchMessage = document.getElementById('search-message')
// 検索結果件数の表示領域
const searchTotal = document.getElementById('search-total')
// 検索結果の表示領域
const searchResults = document.getElementById('search-results')
let searcher: ReturnType<typeof Searcher>
let firstRun = true
searchInput.addEventListener('focusin', (e) => {
searchInit()
})
const fetchJSON = async (url: string) => {
const res = await fetch(url)
return res.json()
}
const showLoadingMessage = () => {
if (!searchMessage) {
return
}
searchMessage.innerHTML = `<div class="text-gray-500 text-sm"><i class="fas fa-circle-notch fa-spin"></i> <span class="ml-1">Loading search indices...</span></div>`
}
const hideLoadingMessage = () => {
if (!searchMessage) {
return
}
searchMessage.innerHTML = ''
}
const showTotal = (results: SearchResult[]) => {
if (!searchTotal) {
return
}
searchTotal.innerHTML = `<div class="text-gray-500 text-sm">${results.length} results</div>`
}
const searchInit = async () => {
if (firstRun) {
searchInput.value = ''
firstRun = false
try {
showLoadingMessage()
const data = await fetchJSON('/index.json')
hideLoadingMessage()
searcher = Searcher(data)
searchInput.addEventListener('keyup', (e) => {
searchExec((e.target as HTMLInputElement).value)
})
} catch (error) {
console.log(`failed to load: ${error}`)
}
}
}
const searchExec = (query: string) => {
const results = searcher.search(query)
showTotal(results)
let searchItems = ''
if (results.length === 0) {
searchItems = ''
} else {
for (const result of results) {
searchItems += `<li class="mb-4">
<a href="${
result.item.permalink
}" class="block flex flex-nowrap mb-1" tabindex="0">
<span class="break-all">${result.item.title}</span>
<span class="dots flex-grow mx-1 mb-2"></span>
<span class="flex-shrink-0">${result.item.date}</span>
</a>
<div class="border-l-8 border-gray-300 pl-2 text-sm">
${highlight(result.firstMatchedPart)}
</div>
</li>`
}
}
if (searchResults) {
searchResults.innerHTML = searchItems
}
}
これでスクリプトは完成した。
Tailwind CSS を使っているなら、未使用 CSS の purge 設定にマークアップを行っているスクリプトを忘れずに追加しよう19。
module.exports = {
purge: [
...
'assets/scripts/**/*.ts', // 追加
],
...
};
検索ページ
最後に、検索ページを作る。ここでは、/search に検索ページを用意する。
まずは、スクリプトを読み込むためにベーステンプレートの </body> 直前に bodyend ブロックを追加する20。
layouts/_default/baseof.html
<!DOCTYPE html>
<html lang="{{ .Language.Lang }}">
{{- partial "head.html" . -}}
<body>
{{- partial "header.html" . -}}
{{- block "main" . }}{{- end }}
{{- partial "footer.html" . -}}
{{- block "bodyend" . }}{{- end }}
</body>
</html>
次に、それを使って検索ページを定義する。
layouts/search/list.html
{{ define "main" }}
<div class="container w-full px-4 my-12">
<div class="w-full mx-auto flex flex-nowrap mb-4">
<div class="mr-4 text-gray-600">
<label for="search-input">
<i class="fas fa-search"></i>
</label>
</div>
<div class="flex-grow">
<input
id="search-input"
class="w-full outline-none bg-gray-200 border-b border-gray-600"
name="q"
tabindex="0"
autocomplete="off"
value=""
placeholder="Type in search terms..."
/>
</div>
</div>
<div class="w-full mx-auto flex flex-nowrap mb-4">
<div id="search-message"></div>
<div class="flex-grow"></div>
<div id="search-total"></div>
</div>
<ul id="search-results" class="w-full mx-auto"></ul>
</div>
{{ end }}
{{ define "bodyend" }}
{{ $opts := dict "minify" (not .Site.IsServer) }}
{{ $built := resources.Get "scripts/search.ts" | js.Build $opts }}
{{ if .Site.IsServer }}
<script type="text/javascript" src="{{ $built.RelPermalink }}"></script>
{{ else }}
{{ $js := $built | fingerprint }}
<script type="text/javascript" src="{{ $js.RelPermalink }}" integrity="{{ $js.Data.Integrity }}"></script>
{{ end }}
{{ end }}
content/search/_index.md
---
title: "Search"
---
以上で、検索機能の実装は完了した。/search にアクセスすれば、検索フォームのあるページが表示されるはずだ。
動作
最初に述べた通り、本サイトの検索ページで本稿で述べた検索機能を試せる。
「aws」で検索したときの結果を図1に示す21。

図1. aws で検索したときの様子
意図した通り、マッチ部分がハイライトされている。
スケーラビリティ
本稿で述べた実装では、サイト内の全ページの全文を含むインデックスを取得している。さらに、検索結果の表示にページネーションを用いていない。 この仕組みはどの程度スケールするだろうか?パフォーマンスはページの平均サイズ、ページ数、検索語長・語数に依存する。本サイトの場合について簡単に考察しておこう。
ページの平均サイズ
本サイトのページの平均サイズは、下記のコマンドで計算する22。
find content/archives -name '*.md' -ls | awk '{sum += $7; n++;} END {print sum/n;}'
結果は、18537.5 bytes だった23。
ページ数
十分に大きいページ数を 1000 と仮定する。
実績から大まかに計算すると、2020 年 1 月から 2021 年 5 月までに 4 ページしか増えていないから、およそ 4 ヶ月に 1 ページのペースである24。 このペースでは、ページ数 1000 に到達するのにかかる時間は 4000 ヶ月、即ち 333 年25であり、筆者が生きている間に到達できる可能性は低い26。 投稿頻度が 1 ヶ月に 1 ページのペースになったとしても、ページ数 1000 に到達するには 83 年ほどかかる。 さらに、週 1 になったとしてもおよそ 20 年だ。
従って、ページ数 1000 の場合に十分なパフォーマンスで検索できれば、実質的にスケーラビリティに問題はないと考えて良い。
ダミーページの生成
パフォーマンス測定のため、ページ数が 1000 になるようにダミーページを生成しよう。そのため、下記の bash スクリプトを用意した27。
scripts/gen-dummy-contents.sh
#!/usr/bin/env bash
set -Eeuo pipefail
script_dir=$(cd "$(dirname "${BASH_SOURCE[0]}")" &>/dev/null && pwd -P)
usage() {
cat <<EOF
Usage: $(basename "${BASH_SOURCE[0]}") [-h] [-v] [-n num] [-b bytes] [-D]
Generates dummy contents for testing.
Requirements:
jq
Available options:
-h, --help Print this help and exit
-v, --verbose Print script debug info
-n, --num The number of contents to generate
-b, --bytes The size of each file's content in bytes
-D, --delete Delete all generated contents
EOF
exit
}
main() {
if [[ delete -eq 1 ]];
then
rm content/archives/dummy-*.md
exit 0
fi
dummy="$(get_dummy $bytes)"
for i in $(seq -f "%04g" 1 $num)
do
hugo new archives/dummy-$i.md
echo "$dummy" >> content/archives/dummy-$i.md
done
}
get_dummy() {
local bytes=$1
curl "https://www.lipsum.com/feed/json?start=yes&what=bytes&amount=${bytes}" 2>/dev/null \
| jq -r .feed.lipsum
}
msg() {
echo >&2 -e "${1-}"
}
die() {
local msg=$1
local code=${2-1} # default exit status 1
msg "$msg"
exit "$code"
}
parse_params() {
num=5
bytes=100
delete=0
while :; do
case "${1-}" in
-h | --help) usage ;;
-v | --verbose) set -x ;;
-D | --delete) delete=1 ;;
-n | --num)
num="${2-}"
shift
;;
-b | --bytes)
bytes="${2-}"
shift
;;
-?*) die "Unknown option: $1" ;;
*) break ;;
esac
shift
done
args=("$@")
return 0
}
parse_params "$@"
main
下記のようにしてダミーページを生成する28。
# -n: ページ数を指定。既存の 4 ページを除いて 996 ページを生成する
# -b: 各ページのサイズ(bytes)。先に算出した平均ページサイズを指定する
./scripts/gen-dummy-contents.sh -n 996 -b 18538
測定
大まかなパフォーマンスが分かれば良いので、Chrome DevTools を使って以下の簡単な測定を行った29。測定は Vercel にデプロイしたものに対して行っている。
検索インデックスの読み込み時間
/index.json (61.2 kB)の読み込み時間を Network タブで確認した(クライアント側のキャッシュは無効にした)。
3 回の測定結果はそれぞれ 1.99 s、1.55 s、1.69 s だった(平均 1.74 s)。
Vercel 側のキャッシュの関係か、少し後に再測定したところ 656 ms という結果も出た。
検索フォームに「a」を入力してから検索結果が表示されるまでの時間
検索フォームに「a」を入力してから検索結果が表示されるまでの時間を Performance タブで測った(1000 件ヒットする)。 結果を図2に示す。
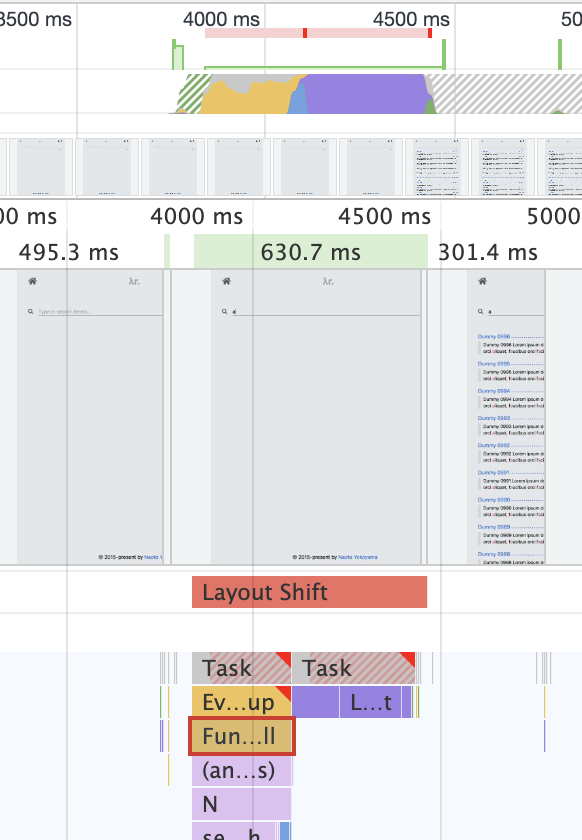
図2. 検索フォームに「a」を入力してから検索結果が表示されるまでの時間。入力から描画までおよそ 630 ms かかった。
入力から描画までの 630 ms のうち、search 関数にかかった時間は 225.9 ms だった。
考察
測定結果から、1000 ページから検索しても利用可能なパフォーマンスが出ることが分かる。
測定結果からは主に検索インデックスの読み込みに時間がかかっているように見えるが、主観的には 1000 件の結果が一度に表示されることによる動作の重さの方が気になった。 また、検索インデックスの読み込み時にはローディングスピナーが表示されるため、それも体感速度に貢献していた。
表示する件数を絞ったりページネーションを行えば、パフォーマンスの改善が期待できる。
おわりに
本稿では、静的サイトにおいて検索機能を実装する方法の一つを示した。 Hugo での他の選択肢は、Search for your Hugo Website | Hugo を見ると良い。 本稿の実装も、そこで触れられている Fast, instant client side search for Hugo static site generator や、それを改善した Super fast, client side search for Hugo.io with Fusejs.io を一部参考にした30。
本サイトではカテゴリやタグを活用していないため検索機能においても無視しているが、必要に応じてカテゴリやタグも検索対象に含めるように拡張すると良い。
付録
Jest and ts-jest
ts-jest を使う。
# 必要なモジュールをインストール
npm install -D jest typescript ts-jest @types/jest
# 設定を追加
npx ts-jest config:init
jest.config.js
module.exports = {
preset: "ts-jest",
testEnvironment: "node",
};
tsconfig.json
{
"extends": "@tsconfig/recommended/tsconfig.json",
"compilerOptions": {
"lib": [
"dom",
"es2020"
]
}
}
テストを実行するには、下記のコマンドを実行すれば良い。
npx jest
Prettier, husky, and lint-staged
Prettier による formatting を husky と lint-staged を使って Git の pre-commit 時に行う。
# Prettier をインストール
npm install -D --save-exact prettier
Prettier の設定を追加する。
.prettierignore
/*
!/assets
/assets/*
!/assets/scripts
.prettierrc
{
"semi": false,
"trailingComma": "es5",
"singleQuote": true,
"tabWidth": 2,
"useTabs": false
}
次に、husky の設定を行う。
npm install --save-dev husky lint-staged
npx husky install
npm set-script prepare "husky install"
npx husky add .husky/pre-commit "npx lint-staged"
package.json を下記のようにする。
package.json
{
...
"scripts": {
"prepare": "husky install"
},
"lint-staged": {
"assets/scripts/**/*.ts": [
"npx prettier --write",
"git add"
]
},
...
}
これで、pre-commit 時に Prettier が自動的にコードを整形して再ステージするようになる。
-
どれほど検索が行われているかは、例えば Google Search Statistics - Internet Live Stats が分かり易い。 ↩︎
-
これらのサービスでもサイトを絞った検索は可能である。DuckDuckGo において「
aws site:www.lambdar.me」 のようにして行える。 Google でも同様である。 ↩︎ -
以降、単に「動的サイト」と書く。 ↩︎
-
以降、単に「静的サイト」と書く。 ↩︎
-
静的サイトと動的サイトの違いについては、例えば Static vs Dynamic Websites - What’s the difference? | GitLab を参照。Next.js に見られるように、近年は SSR (Server-Side Rendering) や SG (Static Generation) によりその境界が曖昧になる場合もある。静的サイトにおいても JavaScript (ECMAScript) を使えば検索機能を実装できることは明らかであり、実現可能性でなく実装方法にのみ興味がある。 ↩︎
-
運用コストを抑えるため。Netlify が遅いので Vercel に移行した | Lambdar で述べた通り、本サイトは Vercel でホストされている。できる限り無料のまま運用したい。 ↩︎
-
一致部分とその周辺のテキストを検索結果として提示した上で、一致部分の色を変えるなどして目立たせるということ。 ↩︎
-
特に重要なことではないが、半角スペースだけでなく、全角スペースも区切り文字にする。 ↩︎
-
但し、大文字と小文字は区別しない。「apple」と「orange」はマッチしないが、「apple」と「APPLE」はマッチする。 ↩︎
-
キーボードで検索条件を入力しているとして、キーアップ時にその時点の検索条件で即座に検索を行い、結果を提示するということ。これにより、入力途中にフィードバックを得ながら検索でき、いちいち検索ボタンを押す必要がなくなる。 ↩︎
-
「apple orange」で検索したとき、「apple」と「orange」の登場回数の合計が多い順に並べるということ。 ↩︎
-
TOML 以外のフォーマットを利用している場合は、拡張子と構文が異なる(
config.yaml、config.json)。 ↩︎ -
ここでは、タイトル(
title)と本文(content)のみを対象に検索するため、この 2 つと表示に使うアドレス(permalink)および作成日(date)以外は省いても良い。 ↩︎ -
jqで pretty-print したもの。また、contentの内容の大部分と 3 つ目以降の要素は省略している。 ↩︎ -
本サイトでは Prettier による formatting を husky と lint-staged を使って Git の pre-commit 時に行っている。それには追加の設定が必要だ(付録を参照)。 ↩︎
-
検索結果を表示するときに改行は反映されないため、単にスペースでつないでも良い。 ↩︎
-
設定しないと、プロダクションビルドではスクリプト内で利用している Tailwind CSS クラスのスタイルが反映されない可能性がある(purge 設定に含まれている他のファイルで利用していない場合に起こる)。 ↩︎
-
このベーステンプレートは例示のために簡単化している。 ↩︎
-
本稿の投稿前に行ったもの。 ↩︎
-
Unix find average file size - Stack Overflow を参考にした。大まかなサイズが分かれば良いので、front matter などのオーバーヘッドについては考慮していない。 ↩︎
-
この計測は本稿投稿前に行った。 ↩︎
-
単純にページの投稿月だけ見て雑に平均を出しているため、正確ではない。また、すぐに分かる通り、この数値の正確さは重要ではない。 ↩︎
-
現状の 4 ページは無視した。 ↩︎
-
但し、Gott の推定を強引に適用すれば、333 年以上生きる可能性はある。1000 年遺るブログのつくりかた | Lambdar の「おわりに」を参照。 ↩︎
-
Minimal safe Bash script template | Better Dev をベースにしている。また、ダミーの内容を生成するために Lorem Ipsum - All the facts - Lipsum generator を利用している。 ↩︎
-
測定には 2020 年発売のラップトップを使用した。CPU は 2.3 GHz Core i7。また、ダウンロード速度が 650 Mbps 程度のネットワーク環境で行っている。 ↩︎
-
はじめはこれらの実装を本サイトでそのまま使う気だったが、古い JavaScript で記述されていたこと、ファジー検索を行っていたこと(Fuse.js を使っている)を理由にやめた。 ↩︎